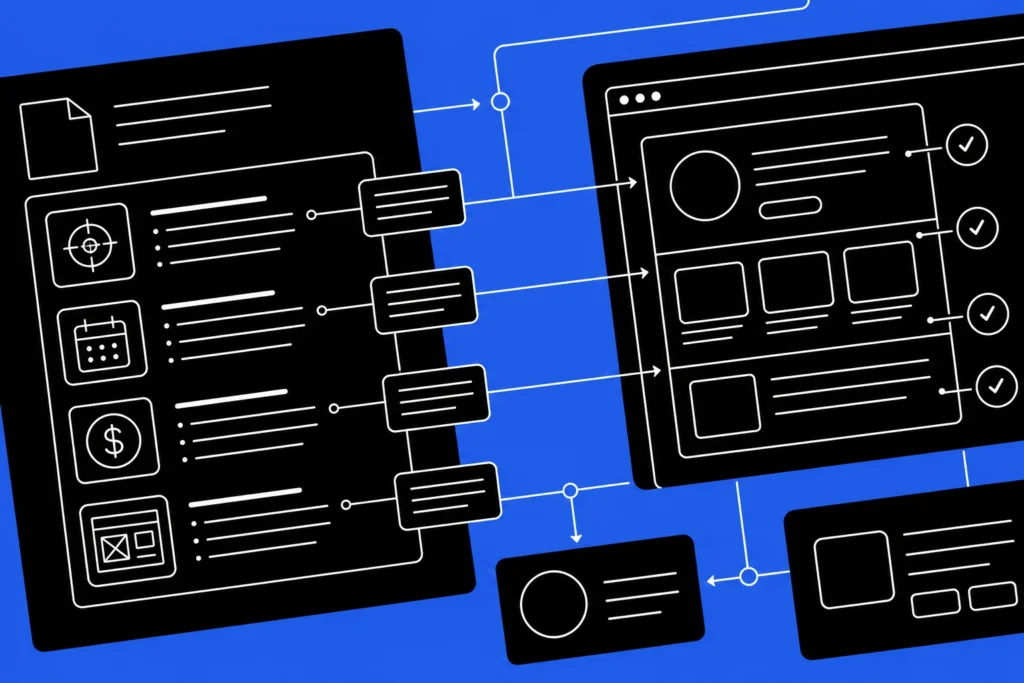
AI search engines work differently than traditional search. They don’t just crawl, index, and rank. They retrieve content, reason through it, and decide which sources to cite in an answer. If your brand isn’t showing up in ChatGPT search results, Google AI Overviews, or Perplexity answers, the problem might not be your content strategy. It might be a retrieval issue, a reasoning gap, or a preference signal you’re not sending.
Most B2B brands assume AI visibility is a content volume problem. They publish more blog posts, optimize harder, and hope the models notice. But when the real issue is broken schema, weak authority signals, or concept relationships AI systems can’t parse, more content just compounds the underlying failure. You end up spending budget on the symptom instead of the diagnosis.
This article introduces a three-layer diagnostic framework: retrieval, reasoning, and preference. Each layer represents a distinct failure mode in AI search visibility. The framework helps you identify which layer is broken before you commit resources to a fix.
Key Takeaways
- AI search visibility requires passing three distinct tests: retrieval (can the model find you?), reasoning (can it connect your concepts?), and preference (does it choose you over competitors?).
- Most brands skip diagnosis and jump straight to content production, wasting budget when the real issue is schema, authority, or conceptual clarity.
- Retrieval failures look like zero visibility in AI answers even when you rank well organically; fixes include structured data, crawlability, and answer-density improvements.
- Reasoning failures look like partial mentions or factual errors in AI-generated answers; fixes include concept tagging, entity relationships, and FAQ structuring.
- Preference failures look like consistent citation of competitors despite comparable content quality; fixes include authority building, external validation, and E-E-A-T signals.
- The right diagnostic sequence matters: fix retrieval before reasoning, reasoning before preference. Skipping steps wastes time and money.
Why AI Search Requires a Different Diagnostic Model
Traditional SEO taught marketers to think in terms of keywords, backlinks, and on-page optimization. If your page wasn’t ranking, you optimized the title tag, built more links, or rewrote the meta description. The feedback loop was clear. Google’s algorithm rewarded specific, measurable inputs.
AI search engines operate on a different model. They don’t rank pages in a list. They synthesize answers from multiple sources, then decide which sources to cite and in what order. The decision happens inside the model’s reasoning layer, not in a traditional ranking algorithm. How ChatGPT search retrieves and ranks sources, published by OpenAI in 2024, explains that citation preference is determined by a combination of retrieval relevance, content quality signals, and reasoning coherence, not keyword density or backlink counts.
This creates three distinct points of failure. Your content might be retrieved but not understood. It might be understood but not preferred. It might not be retrieved at all. Each failure mode requires a different fix. Treating all three as “content problems” leads to misallocated resources and frustration when results don’t improve.
The audit framework isolates which layer is failing so you can address the actual bottleneck. If your content isn’t being retrieved, publishing ten more blog posts won’t help. If it’s being retrieved but misunderstood, adding schema markup matters more than word count. If it’s being understood but not cited, the issue is authority, not information density.

Get the Playbook
Why Your B2B Brand is Invisible in AI Search and How to Fix It
Layer 1: Retrieval (Can AI Models Find You?)
Retrieval is the first gate. If an AI system can’t retrieve your content during its search phase, nothing else matters. You could have the best-written, most authoritative content in your category, and you’ll still be invisible.
Retrieval failures look like this: you rank well in traditional organic search for relevant queries, but you’re never cited in AI-generated answers. Your competitors with weaker content appear in ChatGPT results or Google AI Overviews, but you don’t. You show up in Bing’s traditional results but not in Copilot answers.
The root cause is usually one of three issues: crawlability, structured data, or answer density.
Crawlability and indexability
AI search engines rely on the same foundational web infrastructure as traditional search. If your robots.txt file blocks crawlers, if your important pages are buried behind JavaScript rendering that crawlers can’t parse, or if your page load times exceed tolerance thresholds, retrieval engines won’t surface your content even if it’s excellent.
Check whether your target pages are being indexed at all. Use `site:yourdomain.com “specific phrase from your content”` in Google to confirm. If pages aren’t showing up in traditional search, they won’t be retrieved by AI systems either. Grounding vs indexing in Copilot, a 2024 post from Bing’s webmaster team, clarifies that grounding (the retrieval phase for AI answers) depends on prior indexing. If a page isn’t indexed, it can’t be grounded.
Common crawlability issues in B2B sites include gated content with no preview text, single-page applications that don’t render server-side, and overly aggressive canonicalization that consolidates too much content into too few retrievable URLs.
Structured data and schema markup
AI models don’t just retrieve raw HTML. They prefer content with machine-readable structure. Schema.org markup signals what type of content a page contains (article, FAQ, how-to, product), what entities are mentioned, and how concepts relate to each other.
Pages with Article schema, FAQPage schema, or HowTo schema are more likely to be retrieved as relevant sources because the structured data gives retrieval engines explicit cues about content type and intent. A blog post with FAQ schema is more likely to be pulled into an AI answer for a question-based query than an identical post without it.
This doesn’t mean schema guarantees citation. It means schema improves your odds of clearing the retrieval gate. If you’re failing at Layer 1, implementing structured data is often the highest-leverage fix.
Answer density and extractability
AI retrieval systems favor content that contains concise, extractable answers near the top of the page. If your blog posts bury the answer under 800 words of setup, or if your pages are structured as long-form narrative without clear question/answer pairs, retrieval engines might skip your content in favor of competitors who answer directly.
This is why FAQ sections have become critical for AI visibility. They provide high-density, easily extractable Q&A pairs that retrieval engines can pull verbatim. A post with a strong FAQ section will outperform an otherwise identical post without one, all else equal.
Audit your highest-value pages for answer density. Do they state the answer to the likely query in the first 100 words? Do they include structured Q&A sections? If not, restructuring for extractability often moves the needle on retrieval faster than publishing new content.
Layer 2: Reasoning (Can AI Models Connect Your Concepts?)
Passing the retrieval gate doesn’t guarantee citation. The second failure mode is reasoning. Your content gets retrieved, but the AI model can’t make sense of it. It mentions your brand incorrectly, misattributes a claim, or stitches together fragments from your page with fragments from competitors in a way that garbles your original point.
Reasoning failures look like: partial mentions without full context, factual errors in AI-generated summaries that reference your content, or answers that cite you for generic background information but cite competitors for the specific insight.
The root cause is usually concept ambiguity, weak entity relationships, or insufficient connective structure between ideas.
Concept tagging and entity clarity
AI models build knowledge graphs internally. When they retrieve your content, they map entities (people, companies, products, concepts) and relationships (X causes Y, A is a type of B). If your content uses ambiguous terms, inconsistent naming conventions, or vague references, the model struggles to build a coherent graph.
For example, if you write “our platform” without ever naming the platform explicitly, or if you refer to “AI search” in one paragraph and “generative search” in another without clarifying they’re the same thing, the reasoning layer falters. The model can’t confidently connect the dots.
Fixing reasoning failures requires making concept relationships explicit. Use consistent terminology. Define entities clearly the first time they appear. When you introduce a new concept, state how it relates to concepts you’ve already discussed. This isn’t just good writing. It’s structuring information so reasoning engines can parse dependency chains.
Relationship markers and logical connectives
AI models perform better when you explicitly state cause/effect, comparison, and hierarchical relationships. Phrases like “this leads to,” “as a result,” “in contrast to,” “a type of,” and “prerequisite for” function as reasoning scaffolding. They tell the model how ideas connect.
B2B content often assumes the reader will infer relationships. AI models don’t infer well. They rely on explicit signals. If your content says “implement schema markup” in one section and “improve AI visibility” in another without ever stating that schema markup improves AI visibility by making content more retrievable, the model might not connect the two.
Audit your cornerstone content for relationship clarity. Are causal claims stated explicitly? Are hierarchies clear? If not, adding logical connectives often improves reasoning-layer performance without requiring new content.
FAQ structure as reasoning support
FAQ sections help with both retrieval and reasoning. They improve retrieval by providing extractable Q&A pairs. They improve reasoning by forcing you to state relationships explicitly. Each FAQ answer is a micro-argument: question, direct answer, supporting reasoning.
When AI models encounter well-structured FAQ content, they can extract not just the answer but the reasoning chain that supports it. This makes your content more citation-worthy because the model can confidently explain why your answer is correct, not just that you said it.
If you’re getting partial mentions or misattributions in AI-generated answers, adding or improving FAQ sections is often the fastest fix at Layer 2.
Layer 3: Preference (Do AI Models Choose You Over Competitors?)
Clearing retrieval and reasoning still doesn’t guarantee preference. The third failure mode is competitive. Your content is retrieved, understood, and accurate, but AI systems consistently cite competitors instead. You’re in the consideration set, but you’re not the preferred source.
Preference failures look like: your competitors appear first in AI-generated citations, your brand is mentioned as a secondary or supporting source while competitors are cited as primary authorities, or AI answers paraphrase competitor content but only link your brand as a “see also” reference.
The root cause is usually authority signals, external validation, or E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) deficits relative to competitors.
Authority and external validation
How AI Overviews decide what to cite, published by Google in 2024, states explicitly that citation preference is influenced by the same quality signals used in traditional search: authoritativeness, external validation, and source reputation. If your competitors have stronger backlink profiles, more mentions in authoritative publications, or more recognized authors, AI systems will prefer them even if your content quality is comparable.
This is the hardest layer to fix quickly. Authority is built over time. External validation requires earning mentions, citations, and links from credible third parties. You can’t shortcut this with on-page optimization.
But you can accelerate it. Publish original research that others cite. Get quoted in industry publications. Contribute to authoritative industry reports. Earn speaking slots at recognized conferences. Each external validation signal compounds, gradually shifting preference in your favor.
E-E-A-T signals and author credibility
E-E-A-T and helpful content in the age of AI, a 2024 update to Google’s quality guidelines, emphasizes that AI systems evaluate not just what content says but who says it and why the reader should trust them. First-hand experience, subject-matter expertise, and demonstrated authority all influence preference.
If your blog posts are authored by “Admin” or “Marketing Team” instead of named individuals with visible credentials, you’re losing preference points. If your content reads like recycled summaries instead of original analysis, you’re losing experience points. If you make claims without citing sources or providing evidence, you’re losing trustworthiness points.
Fixing this requires editorial discipline. Assign real authors to content. Include author bios with credentials. Link to the author’s LinkedIn or portfolio. When making claims, cite primary sources. When sharing insights, ground them in first-hand experience or proprietary data.
Competitive differentiation in content positioning
Sometimes preference failures aren’t about absolute authority. They’re about relative positioning. If your content and your competitors’ content all say roughly the same thing in roughly the same way, AI systems have no reason to prefer you. You’re interchangeable.
The fix is differentiation. Take a distinct point of view. Introduce a framework competitors aren’t using. Provide proprietary data or case evidence that others can’t replicate. Structure your argument in a way that makes your reasoning chain clearer or more compelling.
This is where Blennd’s AI visibility strategy work often identifies the highest-leverage moves. It’s not always “write more content.” Sometimes it’s “reframe your core content around a proprietary framework that AI systems can cite as a distinct methodology.”
How to Run the Audit: Sequencing the Diagnostic
The three layers aren’t independent. Reasoning depends on retrieval. Preference depends on reasoning. You can’t skip ahead. If you’re failing at Layer 1, improving Layer 3 won’t help.
Start by testing retrieval. Query your own brand, product names, and core topics in ChatGPT, Perplexity, and Google AI Overviews. Are you showing up at all? If not, the issue is retrieval. Focus on crawlability, schema, and answer density before moving to the next layer.
Once you confirm retrieval, test reasoning. When AI systems cite your content, do they represent your claims accurately? Do they connect your concepts correctly? If you’re getting partial mentions, misattributions, or garbled summaries, the issue is reasoning. Focus on concept clarity, relationship markers, and FAQ structure.
Once reasoning is solid, test preference. Are you being cited, but always after competitors? Are you mentioned as a secondary source when you should be primary? If so, the issue is authority. Focus on external validation, E-E-A-T signals, and competitive differentiation.
This sequencing prevents wasted effort. Many brands jump straight to authority-building tactics (guest posts, backlinks, PR) when their real issue is that AI systems can’t retrieve their content in the first place. Others optimize schema and crawlability when the real issue is weak competitive positioning. The audit framework forces you to diagnose before you prescribe.
Common Mistakes in AI Search Readiness
The most common mistake is assuming AI visibility is just “more SEO.” Brands treat it like an incremental optimization project: add some FAQ schema, write a few more blog posts, wait for results. But if the underlying issue is that your content isn’t being retrieved, or that reasoning engines can’t parse your concept relationships, incremental content won’t move the needle.
The second most common mistake is over-investing in content volume before fixing foundational issues. Publishing 50 blog posts won’t help if none of them have schema markup, if they’re all buried under slow page loads, or if they’re written in a way that reasoning engines can’t extract clear answers from.
The third mistake is ignoring competitive positioning. Even if your retrieval and reasoning are flawless, if your competitors have stronger authority signals and more external validation, AI systems will prefer them. You can’t optimize your way out of an authority deficit. You have to earn it.
The framework prevents these mistakes by forcing a diagnostic sequence. Test retrieval first. Fix what’s broken. Test reasoning second. Fix what’s broken. Then, and only then, invest in authority and differentiation.
What This Means for B2B Marketing Teams
For most B2B brands, AI search readiness isn’t a content project. It’s a cross-functional diagnostic that touches technical infrastructure, editorial process, and competitive strategy.
If your team is structured around traditional SEO roles (content writer, link builder, technical SEO), you’ll need to expand the scope. Retrieval issues often require developer involvement to fix crawlability or implement schema. Reasoning issues require editorial discipline and content architecture changes that go beyond keyword targeting. Preference issues require a long-term authority-building strategy that involves PR, partnerships, and thought leadership, not just on-page optimization.
The audit framework gives marketing leaders a way to diagnose the real bottleneck and allocate resources accordingly. If the issue is retrieval, invest in technical fixes. If it’s reasoning, invest in content restructuring and FAQ development. If it’s preference, invest in external validation and competitive differentiation.
This prevents the common failure mode where brands throw budget at “AI SEO” without knowing which layer is broken, then wonder why results don’t improve.
Frequently Asked Questions
How long does it take to see results from an AI search readiness audit?
Retrieval fixes (schema, crawlability) can show results in 2 to 4 weeks once crawlers re-index your pages. Reasoning improvements (FAQ structure, concept clarity) typically take 4 to 8 weeks as AI systems re-process your content and update their knowledge graphs. Preference improvements (authority building, external validation) take 3 to 6 months minimum because they depend on earning third-party citations and backlinks that AI systems recognize as trust signals.
Can you fix AI visibility without hiring an agency?
Yes, but it requires cross-functional coordination. Retrieval issues need developer support for schema implementation and crawlability fixes. Reasoning issues need editorial discipline and content architecture changes. Preference issues need a sustained authority-building strategy involving PR, partnerships, and thought leadership. Most in-house teams lack the bandwidth or expertise to sequence all three layers effectively, which is why many brands bring in specialists to run the diagnostic and roadmap the fixes.
Do I need to optimize for every AI search engine separately?
Not entirely. The three-layer framework applies universally because all AI search engines rely on retrieval, reasoning, and preference mechanisms. That said, each platform has quirks. Google AI Overviews weight E-E-A-T signals more heavily than Perplexity. ChatGPT favors FAQ-structured content more than Bing Copilot. The diagnostic framework is the same; the tactical emphasis shifts slightly depending on which platforms matter most to your audience.
What if my competitors are getting cited and I can’t figure out why?
This usually indicates a Layer 3 (preference) issue. Your content is being retrieved and understood, but AI systems are choosing competitors because of stronger authority signals, more external validation, or clearer competitive differentiation. The fix isn’t more content. It’s earning third-party citations, getting quoted in authoritative publications, publishing original research, and building external validation that AI systems recognize as trust signals.
Is AI search readiness different for B2C vs B2B brands?
The three-layer framework applies to both, but the tactical emphasis differs. B2C brands often face stronger competition at Layer 3 (preference) because consumer categories have more players and more content saturation. B2B brands more often fail at Layer 2 (reasoning) because their content assumes domain expertise and doesn’t make concept relationships explicit enough for reasoning engines to parse. The diagnostic sequence is the same; the typical bottleneck location shifts.
Should I prioritize traditional SEO or AI search optimization?
False choice. The foundational work overlaps significantly. Crawlability, structured data, and content clarity improve both traditional rankings and AI visibility. Where they diverge, AI search rewards answer density, FAQ structure, and explicit reasoning chains more than traditional SEO does. The right move is to run the audit, identify which layer is failing, and fix that first. In most cases, the fixes improve both traditional and AI search performance simultaneously.
Sources
- How AI Overviews decide what to cite. Google Search Central Blog, 2024.
- How ChatGPT search retrieves and ranks sources. OpenAI, 2024.
- Grounding vs indexing in Copilot. Bing Webmaster Blog, 2024.
- How Perplexity decides which sources to cite. Perplexity AI Blog, 2024.
- E-E-A-T and helpful content in the age of AI. Google Search Central, 2024.
- The state of AI search visibility in 2024. Semrush, 2024.
Need help diagnosing your AI search readiness?
Most B2B brands waste budget optimizing the wrong layer because they skip the diagnostic step. Blennd’s AI search readiness audit maps retrieval, reasoning, and preference gaps before prescribing fixes, so you invest in what actually moves the needle. If you’re not showing up in ChatGPT, Perplexity, or Google AI Overviews and you’re not sure why, we can help you figure out which layer is broken and what to fix first.